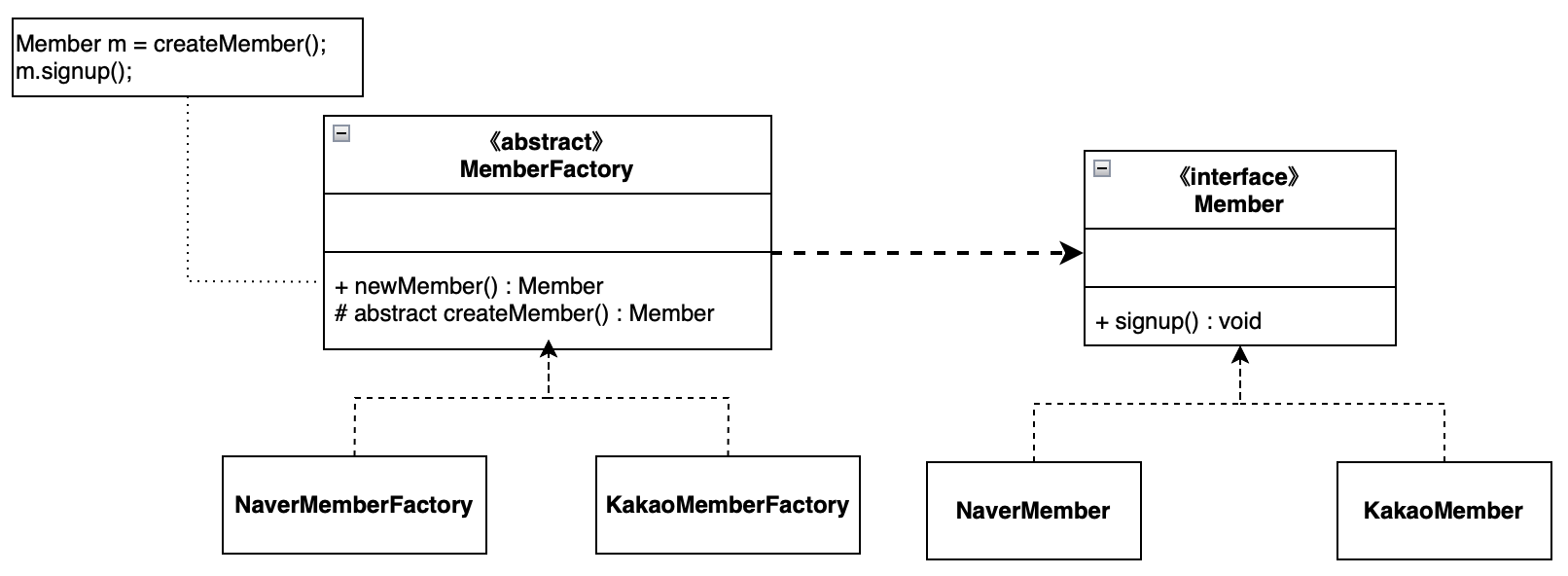
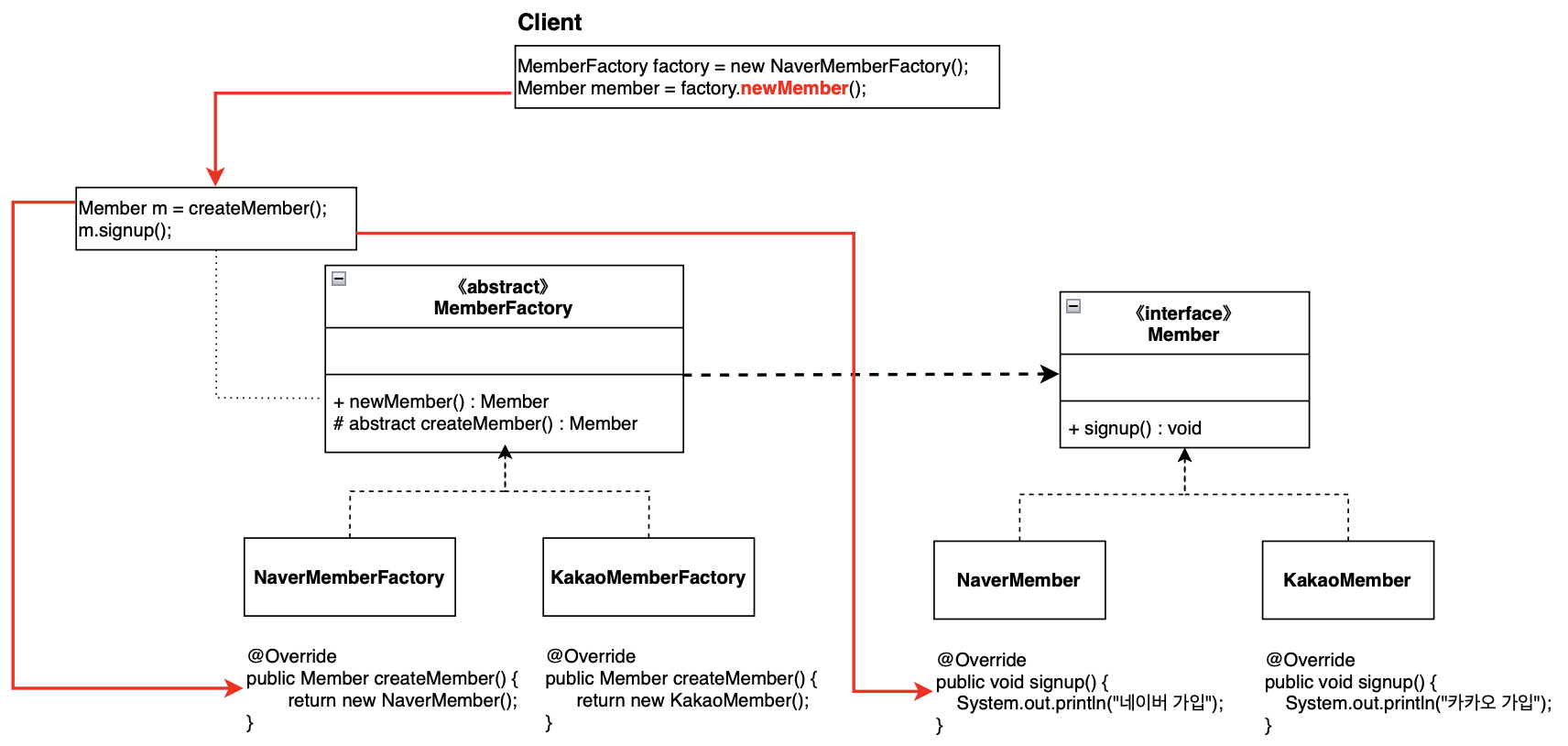
객체 지향 설계 SOLID 원칙
| 두문자 | 약어 | 이름 | 개념 |
| S | SRP | 단일 책임 원칙 Single Responsibility Principle |
한 클래스는 하나의 책임을 가져야 한다. |
| O | OCP | 개방-폐쇄 원칙 Open-Closed Principle |
소프트웨어 개체(클래스, 모듈 등)는 확장에는 열려있으나, 수정에는 닫혀 있어야 한다. |
| L | LSP | 리스코프 치환 원칙 Liskov Substitution Principle |
객체의 정확성을 깨뜨리지 않으면서 상위클래스의 객체를 하위클래스의 객체로 바꿀 수 있어야한다. |
| I | ISP | 인터페이스 분리 원칙 Interface Segregation Principle |
범용적인 인터페이스보다 클라이언트를 위한 인터페이스 여러개가 더 낫다. |
| D | DIP | 의존관계 역전 원칙 Dependency Inversion Principle |
추상화에 의존해야지, 구체화에 의존하면 안된다. |
리스코프 치환 원칙
리스코프 치환 원칙이란 부모 객체와 자식 객체가 있을 때 부모 객체를 호출하는 동작에서 자식 객체로 대체하였을때 정확성을 깨뜨리지 않으면서 완전히 대체 가능해야한다는 원칙입니다.
쉽게 말해 부모객체에서 자식객체로 변경되었어도 문제가 생기지 않아야 한다는 뜻입니다.
LSP 위반 예제
public class Counter {
private List<Member> memberList = new ArrayList<>();
private int count = 0;
public void addAll(List<Member> list) {
for (Member member : list) {
add(member);
}
}
public void add(Member member) {
memberList.add(member);
addCount();
}
protected void addCount() {
count++;
}
public int getCount() {
return count;
}
}
public class Main {
public static void main(String[] args) {
Counter counter = new Counter();
counter.add(new Member());
List<Member> members = List.of(new Member(), new Member(), new Member(), new Member(), new Member());
counter.addAll(members);
System.out.println(counter.getCount()); // 6
}
}
List의 개수를 count를 하는 클래스를 만들었습니다. Counter의 addAll은 자신의 클래스내에 존재하는 add를 호출하여 카운트를 합니다.
public class ArrayCounter extends Counter{
@Override
public void addAll(List<Member> list) {
super.addAll(list);
for (Member member : list) {
addCount();
}
}
}
public class Main {
public static void main(String[] args) {
ArrayCounter counter = new ArrayCounter();
counter.add(new Member());
List<Member> members = List.of(new Member(), new Member(), new Member(), new Member(), new Member());
counter.addAll(members);
System.out.println(counter.getCount()); // 11
}
}addAll 메소드안에서 add 메소드르 호출하는 것을 몰랐던 개발자는 List의 사이즈를 카운트 하기 위해 addCount()메소드를 호출합니다.따라서 ArrayCounter에서 add가 11번이 호출되었고,
그 결과 Counter 객체의 결과는 6, ArrayCounter 객체의 결과는 11이 나왔습니다. 이는 부모객체를 자식객체로 대체되었을 때 완전히 대체되지 않으므로 LSP 위반입니다.
결론
LSP 원칙을 잘 적용한 예제는 우리가 자주 사용하는 컬렉션 프레임워크입니다.
Collection<Integer> collection = new HashSet<>();
collection.add(1);
collection = new TreeSet<>();
collection.add(2);Collection 안에서 Hashset 자료형을 사용하다가 TreeSet으로 변경하더라도 add() 메소드가 동작하는데에는 전혀 문제가 되지 않습니다.
리스코프 치환 원칙은 자바를 배우면서 사용해온 다형성을 규칙으로서 문서화한 것이 LSP 원칙이라고 생각하시면 됩니다.