
프로토타입 패턴
프로토타입(Prototype) 패턴은 객체를 생성하는 비용이 높은 경우, 기존 객체를 복제하여 새로운 객체를 생성하는 패턴입니다.
다시 말해 기존의 객체를 새로운 객체로 복사하여 우리의 필요에 따라 수정하는 메커니즘을 제공합니다.
이 프로토타입 패턴은 객체를 생성하는 데 비용이 많이 들고, 이미 유사한 객체가 존재하는 경우에 사용됩니다. DB로부터 가져온 데이터를 수차례 수정해야하는 경우 new 라는 키워드를 통해 객체를 생성하는 것은 비용이 너무 많이 들기 때문에 한 번 DB에 접근하여 객체를 가져오고 필요에 따라 새로운 객체에 복사하여 데이터를 수정하는 것이 더 좋은 방법입니다.
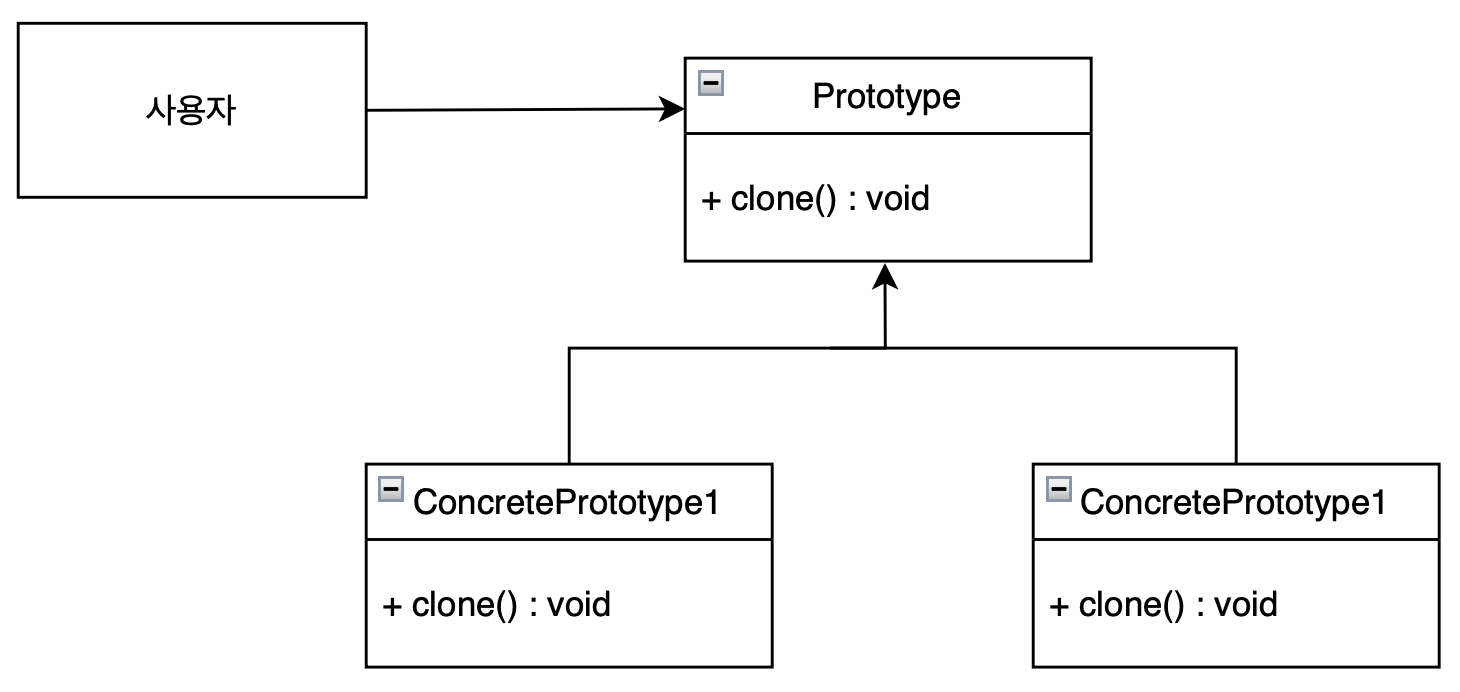
프로토타입 패턴 구현
Java에서는 이 패턴을 구현하기 위해 Cloneable 인터페이스를 사용합니다. Cloneable 인터페이스는 마커(marker) 인터페이스로, 별도의 메소드가 정의되어 있지 않습니다. 이 인터페이스를 구현하는 클래스는 얕은 복사 (shallow copy) 를 지원한다는 표시입니다.
Cloneable 인터페이스를 구현하는 이유는 clone() 메소드를 호출하여 객체를 복제하기 위함입니다. clone() 메소드는 Object 클래스에서 상속받은 메소드 중 하나로, 복제 가능한 객체에서 호출할 수 있습니다. 그러나 Cloneable을 구현하지 않은 객체가 clone()을 호출하게 되면, CloneNotSupportedException이 발생합니다.
public class Cookie{
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
public class Main {
public static void main(String[] args) throws CloneNotSupportedException {
Cookie cookie = new Cookie();
cookie.clone(); // CloneNotSupportedException 발생!
}
}
따라서 Cloneable 인터페이스를 구현함으로써 해당 클래스의 인스턴스가 복제 가능하다는 것을 나타내고, 이를 통해 프로토타입 패턴을 적용할 수 있게 됩니다. 하지만 주의할 점은 clone() 메소드는 얕은 복사를 수행하므로, 필요에 따라서 깊은 복사(Deep Copy)를 구현해야 할 수 있습니다.
얕은 복사
얕은 복사 (Shallow Copy)는 객체의 필드들을 복제할 때, 참조 타입의 필드는 원본 객체와 복제된 객체가 같은 인스턴스를 참조합니다.
public class ShallowCopyExample implements Cloneable {
private int value;
private int[] array;
public ShallowCopyExample(int value, int[] array) {
this.value = value;
this.array = array;
}
@Override
public ShallowCopyExample clone() throws CloneNotSupportedException {
return (ShallowCopyExample) super.clone();
}
public static void main(String[] args) throws CloneNotSupportedException {
int[] originalArray = {1, 2, 3};
ShallowCopyExample original = new ShallowCopyExample(42, originalArray);
ShallowCopyExample cloned = original.clone();
// 값과 배열은 복제되지만 배열은 같은 배열을 참조하고 있음
System.out.println(original == cloned); // false
System.out.println(original.array == cloned.array); // true (얕은 복사)
}
}
깊은 복사
깊은 복사 (Deep Copy) 는 참조 타입의 필드도 새로운 인스턴스를 생성하여 복사하게 됩니다. 즉 모든 필드 변수들이 새로운 인스턴스를 가집니다.
public class DeepCopyExample implements Cloneable {
private int value;
private int[] array;
public DeepCopyExample(int value, int[] array) {
this.value = value;
this.array = array.clone(); // 깊은 복사: 배열의 복사본을 생성하여 참조
}
@Override
public DeepCopyExample clone() throws CloneNotSupportedException {
return (DeepCopyExample) super.clone();
}
public static void main(String[] args) throws CloneNotSupportedException {
int[] originalArray = {1, 2, 3};
DeepCopyExample original = new DeepCopyExample(42, originalArray);
DeepCopyExample cloned = original.clone();
// 값은 복제되고 배열은 복제본을 참조하고 있음
System.out.println(original == cloned); // false
System.out.println(original.array == cloned.array); // false (깊은 복사)
}
}
프로토타입 패턴 구현 예제
public class Employee implements Cloneable {
private String name;
private int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
@Override
protected Employee clone() {
try {
return (Employee) super.clone();
} catch (CloneNotSupportedException e) {
throw new RuntimeException(e);
}
}
}
public class Employees {
private final List<Employee> employeeList;
public Employees(List<Employee> employeeList) {
this.employeeList = employeeList;
}
public List<Employee> getCloneList() {
List<Employee> clone = new ArrayList<>();
for (Employee employee : employeeList) {
Employee cloneEmployee = employee.clone();
clone.add(cloneEmployee);
}
return clone;
}
public List<Employee> getOriginalList() {
return employeeList;
}
}
Cloneable를 사용하는 Employee 에 clone() 메소드를 오버라이드 했고, 그 리스트를 담은 Employees 에 비교를 위해 cloneList와 originalList 메소드를 구현했습니다.
public class Main {
public static void main(String[] args) throws CloneNotSupportedException {
Employee emp1 = new Employee("김OO", 20);
Employee emp2 = new Employee("이OO", 22);
Employee emp3 = new Employee("박OO", 25);
Employee emp4 = new Employee("오OO", 29);
Employee emp5 = new Employee("나OO", 23);
List<Employee> employeeList = List.of(emp1, emp2, emp3, emp4, emp5);
Employees employees = new Employees(employeeList);
List<Employee> originalList = employees.getOriginalList(); // 같은 인스턴스
List<Employee> cloneList = employees.getCloneList(); // clone 인스턴스
System.out.println(employeeList == originalList); // true
System.out.println(employeeList == cloneList); // false
Employee originalEmp = employeeList.get(0); // 같은 인스턴스의 첫번째 Employee
Employee cloneEmp = cloneList.get(0); // clone 인스턴스의 첫번째 Employee
System.out.println(originalEmp == cloneEmp); // false
}
}
프로토타입 패턴의 장/단점
프로토타입 패턴은 객체를 복제하여 새로운 객체를 생성하는 패턴으로, 이를 통해 객체 생성의 비용을 줄일 수 있습니다. 하지만 프로토타입 패턴은 특정 상황에서 유용하게 사용될 수 있지만, 모든 상황에서 적합하지는 않습니다.
장점
- 객체 생성 비용 감소 : 객체를 복제함으로써 새로운 객체를 생성할 때의 비용을 줄일 수 있습니다. 특히 복잡한 객체 구조이거나 생성에 많은 리소스가 필요한 경우에 유용합니다.
- 동적 객체 생성 : 런타임에서 동적으로 객체를 생성할 수 있습니다. 사용자가 필요에 따라 객체를 생성하고 조작할 수 있습니다.
- 객체 생성 시간 단축 : 객체를 복제하여 생성하기 때문에 클래스의 초기화나 설정 작업을 생략할 수 있어 객체 생성 시간을 단축할 수 있습니다.
단점
- Cloneable 인터페이스의 한계 : 프로토타입 패턴을 구현하기 위해서는 Cloneable 인터페이스를 필연적으로 사용하게 되는데 이 인터페이스는 마커(marker) 인터페이스이고, clone() 메소드는 얕은 복사만을 수행하기 때문에 깊은 복사를 수행하려면 추가적인 작업이 필요합니다.
- 복제과정의 복잡성 : 객체가 복잡한 구조를 가지거나 참조하는 객체들이 많다면, 이를 적절하게 복제하려면 복잡한 복제 과정이 필요할 수 있습니다. 특히 객체 그래프가 순환이 발생하는 경우에 복제 과정이 더욱 복잡해질 수 있습니다.
- 메모리 사용량 증가 : 객체를 복제하여 생성하면 메모리 사용량이 증가할 수 있습니다. 특히 객체가 큰 데이터를 가지고 있거나 복제 해야 할 객체 수가 많을 수록 사용량이 증가합니다.
프로토타입 패턴의 사용여부는 특정 상황과 요구사항에 따라 주의 깊게 고려하여 사용해야합니다.
'디자인패턴 > 생성' 카테고리의 다른 글
| 자바(JAVA) - 싱글톤 패턴(Singleton Pattern) (0) | 2024.02.23 |
|---|---|
| 자바(JAVA) - 팩토리 메소드 패턴(Factory Method Pattern) (0) | 2024.01.30 |
| 자바(JAVA) - 빌더 패턴(Builder Pattern) (0) | 2024.01.29 |
| 자바(JAVA) - 추상 팩토리 패턴(Abstract Factory Pattern) (0) | 2024.01.22 |







